
中国几千年辉煌的华夏文明,留下了海量的古籍文献资料,这些文字记录反映了当时社会在政治、军事、经济、科技、教育、文化等各个领域的状况,承载着丰富的历史信息和文化传承。但是,现在大部分人都很难流畅地阅读和理解古籍文献,利用先进的AI技术可以让普通人能读懂古籍、理解古籍,也为挖掘和利用古籍文献中蕴含的丰富知识提供了技术支撑。金连文教授带领的“深度学习与视觉计算实验室”基于大语言模型技术构建了面向古籍透彻理解的数字人文大模型——通古大模型。通古大模型以该实验室曾在EvaHan2023古籍文白翻译国际比赛中获得冠军的大模型为基座,结合自动生成的对话模板和金连文教授团队在古籍领域长期积累的丰富大数据资源,通过大模型指令微调技术训练而得。通古大模型在文白翻译、句读标点和古籍检索等领域均有出色的表现。此外,该模型以自然对话的形式,融合多种任务,使得大众了解中国传统文化更加便捷有效,形式更加亲切自然,有助于中华文化的传播和发扬光大。





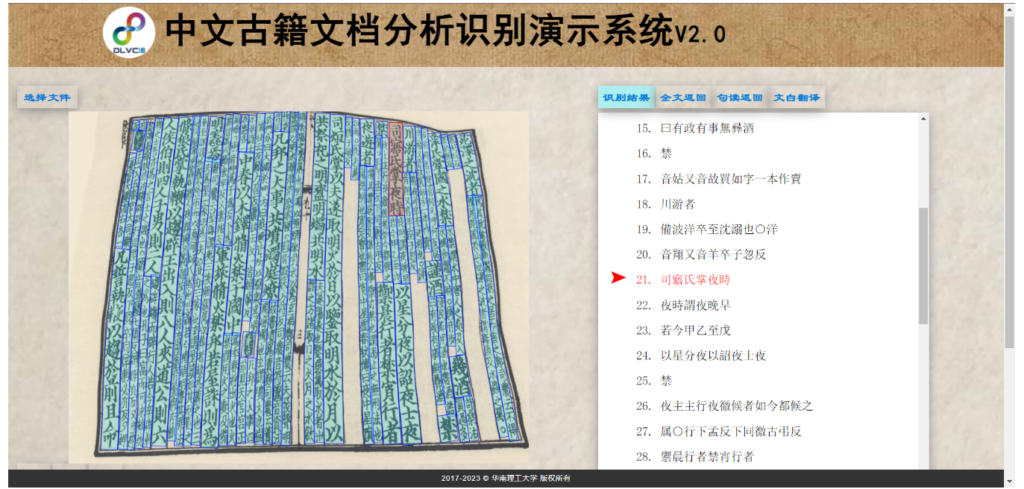
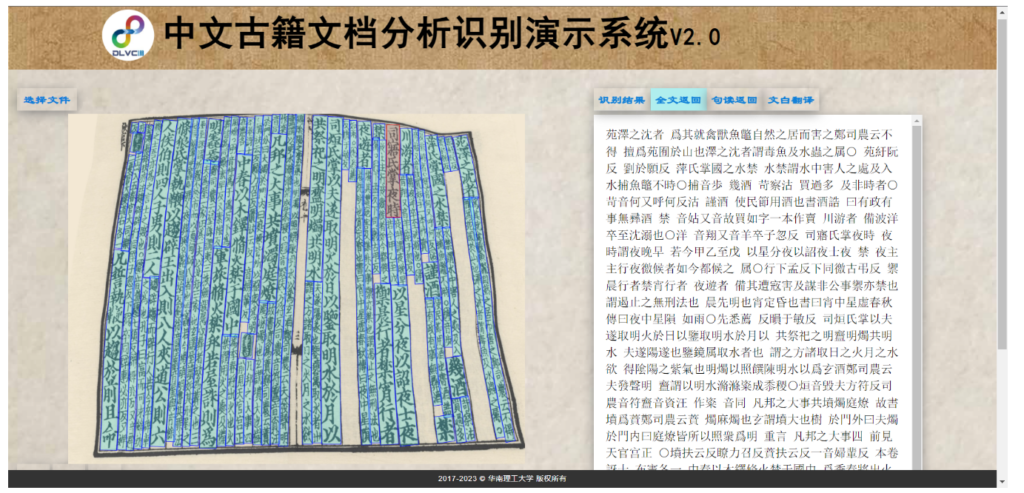
金连文教授团队还开发了一个业内先进的古籍文档分析与识别系统(相关技术曾荣获2019年首届数字中国创新大赛“文化传承——汉字多场景识别” 赛道第一名及总决赛唯一最佳算法能力奖、2022年首届大湾区国际算法算例大赛-古籍图像分析与识别竞赛冠军)。用户只需要提供一张古籍图片,系统即能够自动识别并定位其中所有的文本,并将识别出的文本按照正确的阅读顺序排序。系统还集成了该团队自主研发的古籍句读(自动标点)和文本翻译两大功能,能够自动为识别出的文本添加标点符号、翻译为现代文,便于现代人能看懂古文。
这一系统经过了精心的算法优化,以应对古籍文档在现实场景中可能出现的各种挑战,例如书本的弯曲、倾斜、密集以及低分辨率等问题,这些问题是现有其他系统难以应对的。因此,该系统具备出色的实用性和鲁棒性,为推动古籍数字化工作提供了有力支持,有助于传承和弘扬中华优秀传统文化。

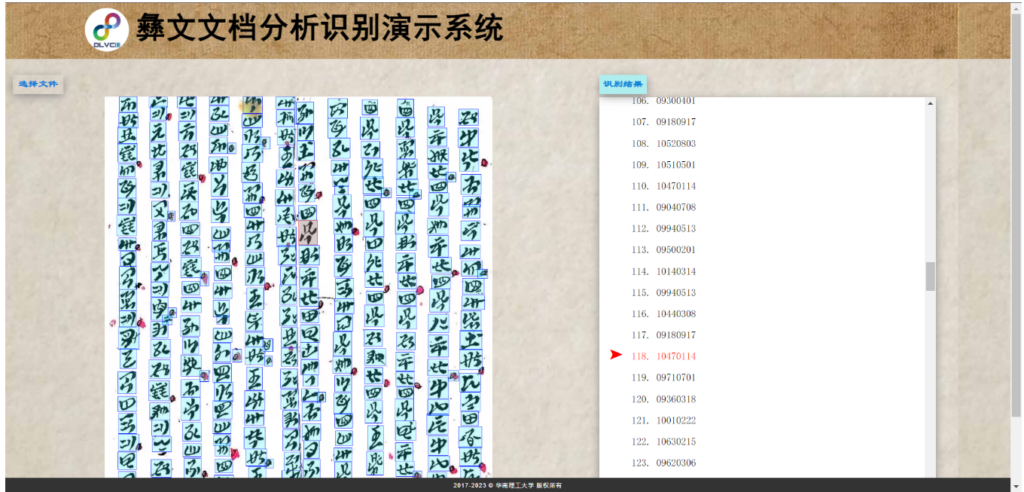
此外,团队还开发了彝文文档分析识别系统,该系统旨在应对古彝文图片的挑战,能够自动精确地定位并辨识图片中的彝文文字(以自定义编码给出输出)。这项识别技术采用的彝文编码是基于上海大学、上海合合信息科技公司、本团队今年早前联合发布的业界首个古彝文基础编码数据库而进行。
文言文是中国传统文化的载体,AI古籍图像识别及文言文翻译技术有助于人们增进对古代中国历史的了解,促进中华优秀传统文化的传承。此外,AI文言文翻译技术可以促进国际间交流理解,降低文化鸿沟,让外国读者也可以通过翻译认识中国历史文化,提高我国在国际上的文化影响力。2017年1月25日,中共中央办公厅、国务院办公厅发布了《关于实施中华优秀传统文化传承发展工程的意见》,这是我国政府为建设社会主义文化强国、增强国家文化软实力、实现中华民族伟大复兴的中国梦印发的文件,对如何实施中华优秀传统文化传承发展工程做出了重要指导性规划。2022年4月,中共中央办公厅、国务院办公厅印发了《关于推进新时代古籍工作的意见》,指出“做好古籍工作,把祖国宝贵的文化遗产保护好、传承好、发展好,对赓续中华文脉、弘扬民族精神、增强国家文化软实力、建设社会主义文化强国具有重要意义。”AI古籍文字识别及文言文翻译技术对促进古籍文化传承与发展、弘扬民族精神、增强国家文化软实力,对推动中国古籍文物数据挖掘、知识发现、智能化开发与利用等领域的技术进步有重要意义。