Nanfang Metropolis Daily
Recently, Stanford University released the Artificial Intelligence Index Report 2022. This is the fifth consecutive year that Stanford has released a report in the field of artificial intelligence, and in this year's report, China ranked first in terms of publication and citation of relevant journals.
The report also notes that as the capabilities of AI systems, such as natural language processing, image recognition and other technologies, are rapidly increasing, so too is their bias and harmfulness, which is contributing to the building of ethical and legal domains in various countries, with 55 bills related to artificial intelligence passed in 25 countries over a five-year period.
China publishes the most papers and has the highest number of US-China co-authorships in the world
Behind the rapid development of AI, the power of research and development is indispensable. From 2010 to 2021, the total number of AI publications doubled from 160,000 to 330,000, including journal articles, conference papers and academic papers.
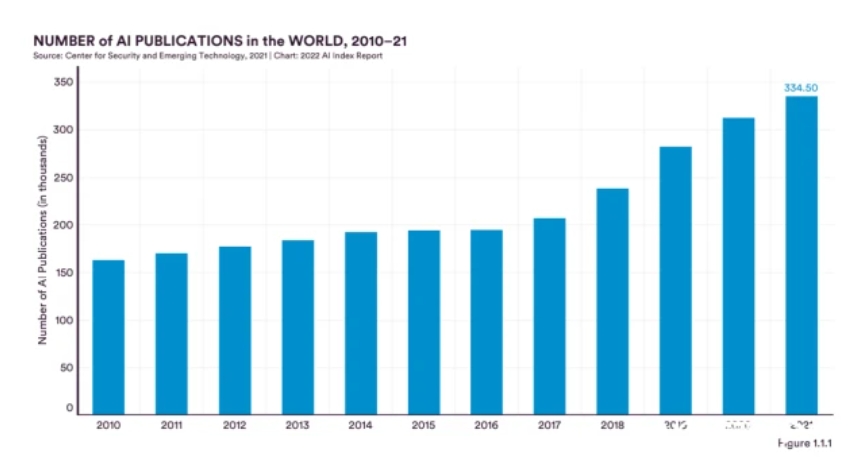
Among them, publications in pattern recognition and machine learning have grown at a faster rate, and the total number has doubled since 2015. In contrast, other areas that have been heavily influenced by deep learning have seen less growth, including computer vision, data mining and natural language processing.
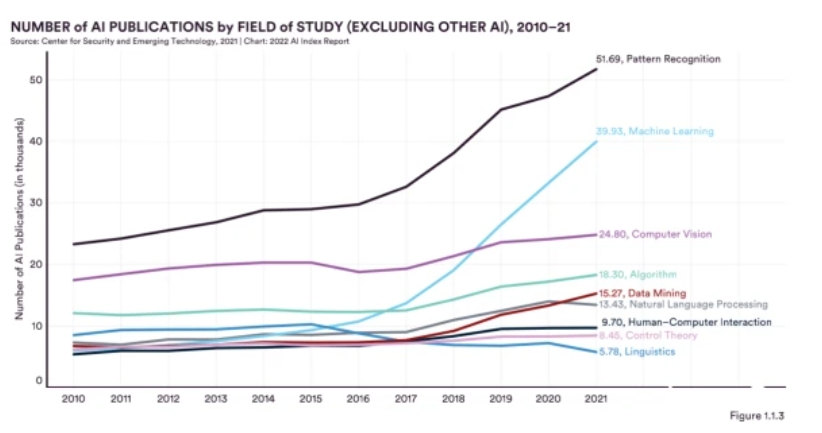
Regionally, East Asia and the Pacific leads with 42.9 per cent of journal publications in 2021, followed by Europe and Central Asia (22.7 per cent) and North America (15.6 per cent). In addition, South Asia, the Middle East and North Africa show the most significant increase, with the number of AI journal publications increasing by about 12 and 7 times, respectively, over the past 12 years.
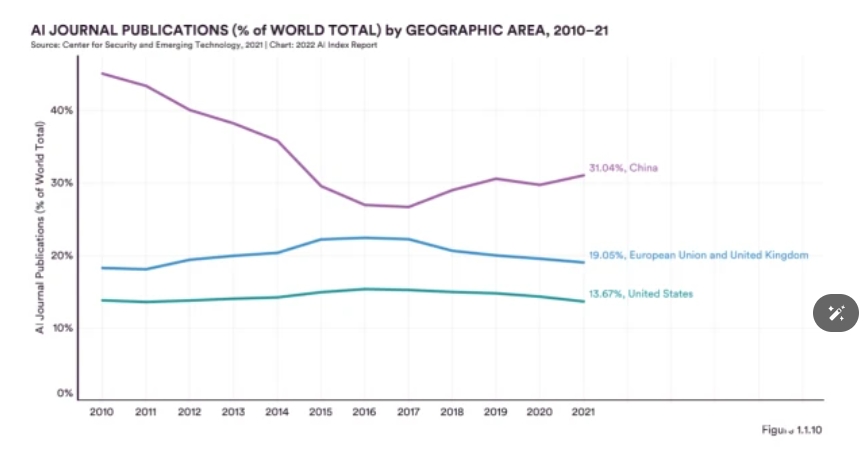
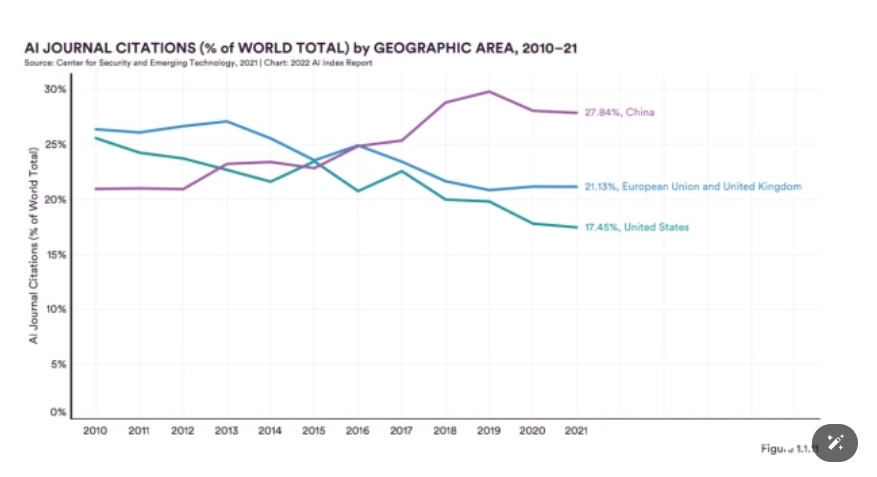
China, on the other hand, maintains its leading position in terms of the number of papers. Since 2010, China has perennially held the top spot in terms of the number of papers. Last year, China continued to be the world leader in the number of publications contributed to AI journals, conferences and knowledge bases - the sum of all three publication types was 63.2 per cent higher than that of the US. At the same time, the citation rate of journal papers led the world with 27.84 per cent.
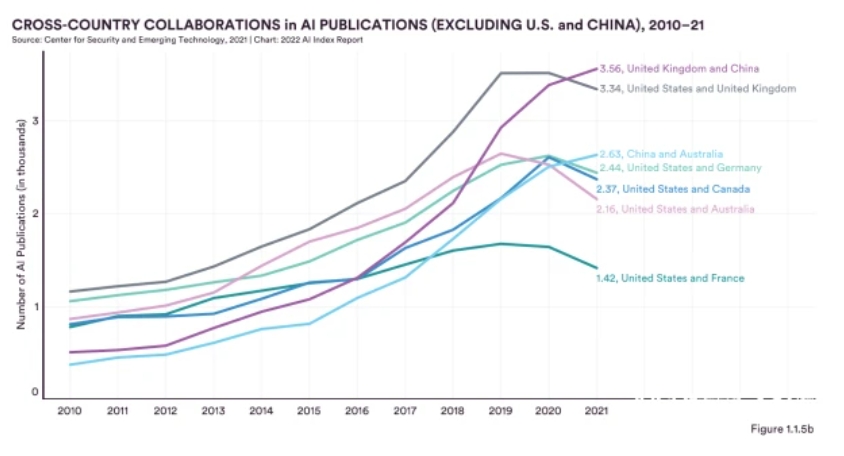
Notably, despite rising geopolitical tensions, the United States and China have collaborated on the largest number of transnational AI publications in the 11-year period from 2010 to 2021, with a fivefold increase since 2010. The number of collaborative publications between the United States and China is 2.7 times higher than the number of collaborative publications between the United Kingdom and China, which is the second highest ranking in this category.
Large Language Models More Likely to Reflect Bias, Ethical Regulation Needs to Keep Up
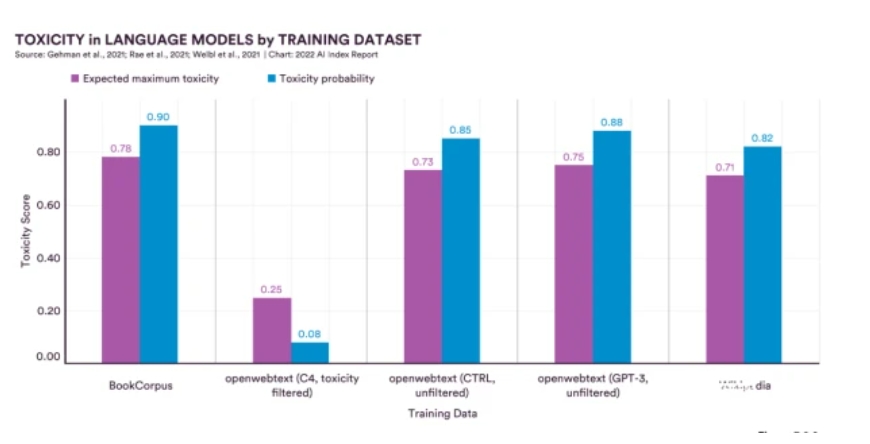
Natural Language Processing (NLP) in this year's report data performance is not very bright, but the report highlights its training data in the bias (bias) problem.
The data show that large language models are better able to reflect bias from training data. natural language models developed in 2021 with 280 billion parameters showed a 29% increase in toxicity compared to models with 117 million parameters in 2018. This phenomenon is common across multiple public corpus sites, and much of the harmfulness of language models comes from unfiltered underlying training data.
Machine translation systems have also been shown to reflect and amplify social biases in their data sets. Stanford University used benchmark data from WinoMT, and the models measure bias in machine translation by comparing original and translated gender pronouns, such as whether "she" is translated as "he" or "he" as "she", when English statements are translated into other languages. The models measure bias in machine translation by comparing the original and translated gender pronouns, such as whether "she" is translated as "him" or "her".
The results of the data proved that in most of the languages tested, the male gender translators were slightly more accurate than the female gender.

In addition to this, bias in multimodal model learning has also caught the attention of researchers. While rapid progress has been made in multimodal language vision modelling in recent years, setting many new records on tasks such as image classification and creating images from text, they also reflect social stereotypes and prejudices, with the report noting that images of black people were misclassified as non-human at more than twice the rate of any other race.
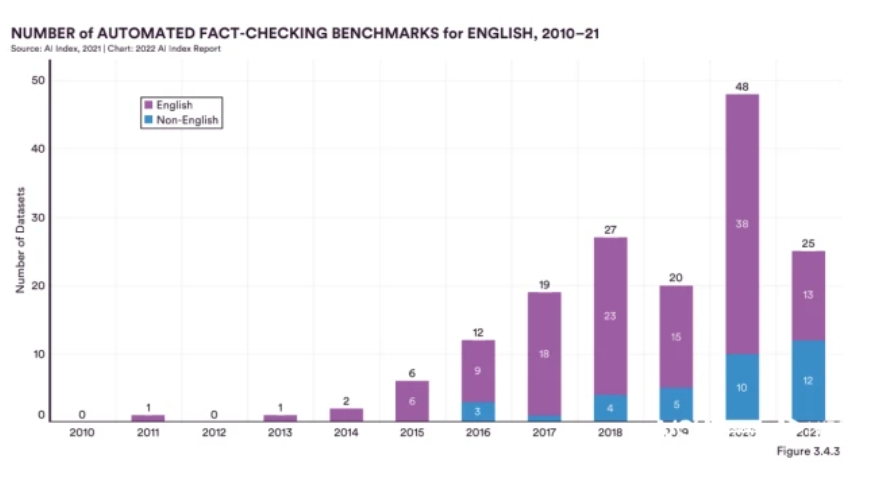
Happily, research on AI transparency and fairness has also exploded since 2014. Publications related to AI ethics have more than quintupled. Industry researchers have seen a 71 per cent year-on-year increase in publications presented at AI ethics conferences in recent years. On top of this, automated fact-checking datasets have grown year-on-year since 2010, with 25 new ones added in 2021, including 12 non-English datasets.
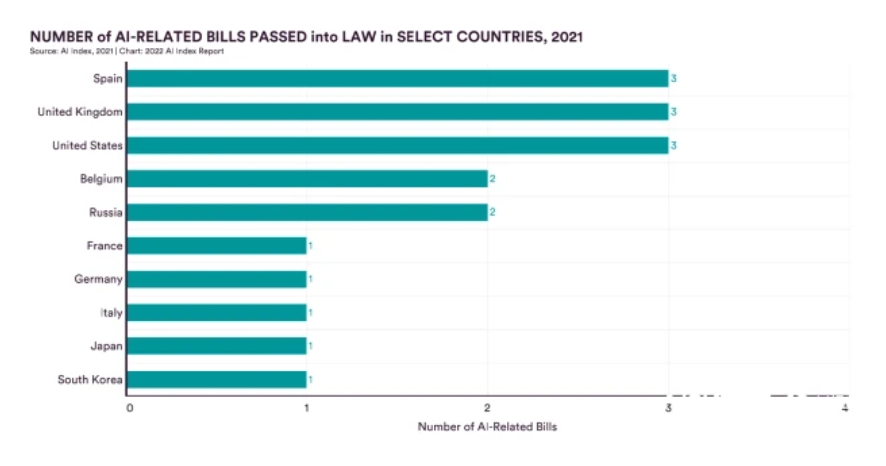
Beyond ethics, individual countries are also increasing their efforts in the legal governance of AI. From 2016 to 2021, a total of 25 countries have passed 55 bills related to AI, with the United States topping the list. Since 2017, three new bills have been passed in the U.S. every year, and 13 bills have been released so far. The U.S. is followed by Russia, Belgium, Sibanye, and the United Kingdom. And Spain, the UK and the US lead the way in terms of the number of laws enacted in 2021, with three issued each
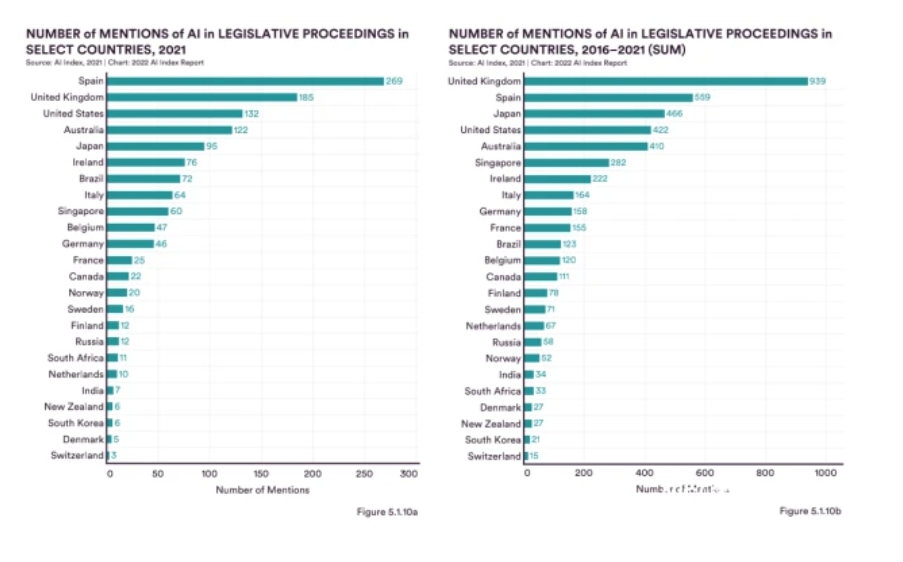
This does not mean that other countries have no intention of regulating AI. The report mentions a total of 1,323 references to AI in the legislative processes of 25 countries counted in 2021. Among them, Spain, the UK, the US, Australia and Japan are at the top of the list.